






Projet HAPROXY + SLOWLORIS
1. Environnement LAB
- Nous utiliserons pour ce projet des VMwares avec un système d’exploitation Linux sous Parrot pour les 3 VMS
- Les IPs ne seront pas en 192.168.1.X mais en 192.168.20.X car nous sommes sur le TP Link.

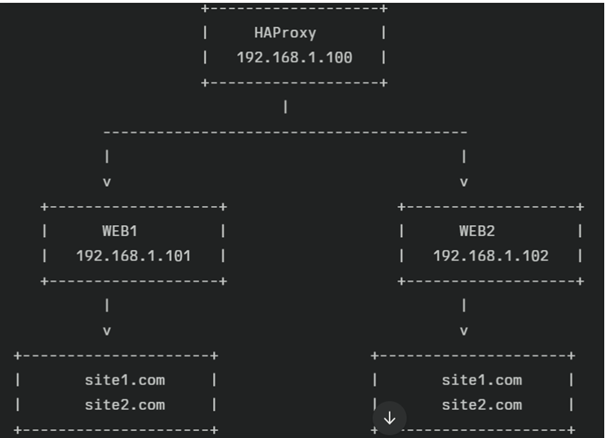
2. Présentation du HAProxy ?
HAProxy (High Availability Proxy) est un logiciel open source utilisé principalement comme reverse proxy et load balancer sur Linux. Il sert à répartir intelligemment le trafic réseau (HTTP, TCP…) entre plusieurs serveurs backend pour améliorer la performance, la fiabilité et la scalabilité des applications web.
2.1 À quoi ça sert :
- Répartition de charge (Load balancing) : distribue les requêtes entre plusieurs serveurs pour éviter la surcharge.
- Haute disponibilité : si un serveur tombe, HAProxy le détecte et redirige automatiquement les requêtes vers les serveurs encore disponibles.
- Terminaison SSL : peut gérer le chiffrement/déchiffrement HTTPS.
- Proxying : agit comme un intermédiaire entre les clients et les serveurs pour des raisons de sécurité ou d’optimisation.
2.2 Pourquoi l’utiliser :
- Léger, rapide, très performant
- Très utilisé dans les infrastructures web modernes
- Compatible avec Docker, Kubernetes, etc.
3. Présentation d’un serveur Frontend et Backend
3.1 Serveur Frontend (côté client)
Le Frontend est la partie du serveur HAProxy qui reçoit les requêtes entrantes des clients (navigateurs web, applications, etc.).
Il est en quelque sorte la porte d’entrée du trafic.
Caractéristiques principales :
- Écoute sur une IP et un port (ex :
0.0.0.0:80pour HTTP). - Peut appliquer des règles (filtrage, redirections, SSL…).
- Transmet les requêtes au bon backend selon la configuration.
3.2 Serveur Backend (côté serveurs applicatifs)
Le Backend est la partie qui contient la liste des serveurs réels (serveurs web, bases de données, APIs, etc.) vers lesquels les requêtes sont envoyées depuis le frontend.
Caractéristiques principales :
- Contient plusieurs serveurs physiques ou virtuels.
- Gère l’algorithme de répartition de charge (
roundrobin,leastconn, etc.). - Peut faire des vérifications d’état (health checks) sur les serveurs.
4. Installation des serveurs Apache2 sur Linux
Pour commencer il est important de rester en Bridged pour pouvoir téléchargé Apache2.
Ouvrer votre terminal et c’est parti.
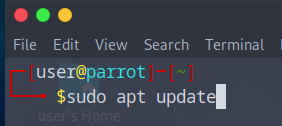
Saisissez les commandes suivantes :
- Sudo apt update
- Sudo apt install apache2
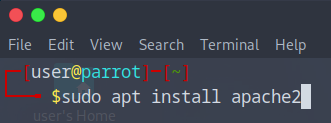
Confirmer avec « Y » pour continuer l’installation.
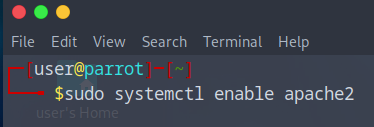
Pour qu’Apache démarre automatiquement en même temps que Debian, saisissez la commande ci-dessous (même si normalement c’est déjà le cas) :
- Sudo systemctl enable apache2
Ensuite pour le faire démarrer entrer cette commande
- Sudo systemctl start apache2
Nous allons effectuer un status pour voir que tout fonctionne bien
- Sudo systemctl status apache2
- Si tout va bien vous devriez avoir le service en enabled, et active (running).
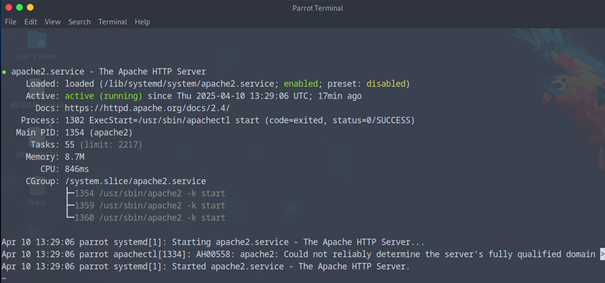
Notre serveur Apache est installer et activé, à reproduire sur le 2eme serveur WEB également.
5. Configuration et Création de Virtualhost pour nos serveur Apache2
5.1 Qu’est-ce qu’un VirtualHost ?
Un VirtualHost est une configuration qui permet de diriger le trafic vers le bon site en fonction du nom de domaine demandé par le navigateur.
5.2 Où sont stockés les VirtualHosts ?
Sur une distribution Linux comme Debian ou Ubuntu :
- Fichiers de configuration :
/etc/apache2/sites-available/ - Liens actifs :
/etc/apache2/sites-enabled/
5.3 Explication des lignes VirtualHosts :
VirtualHost *:80: écoute toutes les adresses IP sur le port 80 (HTTP)ServerName: le nom de domaine principalServerAlias: autres noms qui pointent vers ce site (ex. :www.mon-site.com)DocumentRoot: dossier où se trouvent les fichiers HTML/PHP du siteErrorLogetCustomLog: chemins des logs d’erreur et d’accès
5.4 Ouverture des Ports 8080 et 8081
Vu que nous voulons faire du loadbalancing le faire uniquement sur le port 80 serait inutile
Faire un 50/50 sur WEB1 site1.com/site2.com 192.168.1.101:80 reviendrais à faire du 100%, vu qu’on envoie tout sur le même port.
Donc pour pas nous compliquez la tache on va ouvrir 2 nouveaux ports qu’qu’on mettra en écoute
- Site1.com aura le port 8080
- Site2.com aura le port 8081
Pour cela il va falloir aller modifier ports.conf dans /etc/apache2
*
– Et rajouter nos deux nouveaux ports.
Listen 8080
Listen 8081
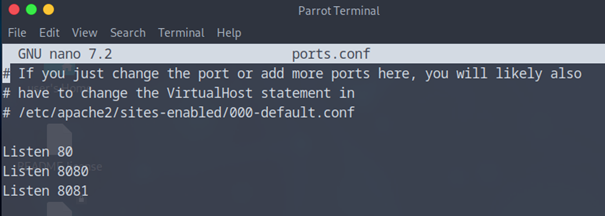
N’oublier pas de reproduire cela sur votre deuxième serveur WEB
5.5 Configuration de nos VirtualHosts
Ce qu’il faut savoir c’est qu’il va nous falloir deux virtualhosts par serveur Apache pour créés une redondance.
Donc si nos calculs sont bons on devrait avoir 4 virtualhosts.
Pour commencer il va falloir aller sur notre serveur Apache Web1, ouvrezz le terminal
Ensuite rendez-vous à ce chemin cd /etc/apache2/sites-available/ ensuite faites un ls
Vous devriez voir que deux fichiers 000-default.con et default-ssl.conf
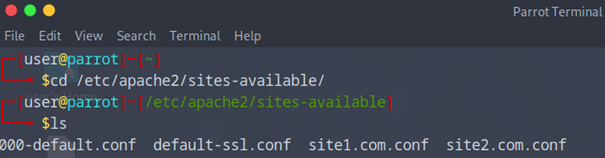
Nous allons donc créés nos deux virtualhosts pour cela on va faire deux nouveaux fichiers.
Pour le site1 saisissez cette commande :
- Sudo touch site1.com.conf

La même chose pour le site2 :
- Sudo touch site2.com.conf

Maintenant que nos deux fichiers sont créés nous allons les modifier avec nano
- Sudo nano site1.com.conf
- Bien mettre le <VirtualHost * :8080> pour le site 1
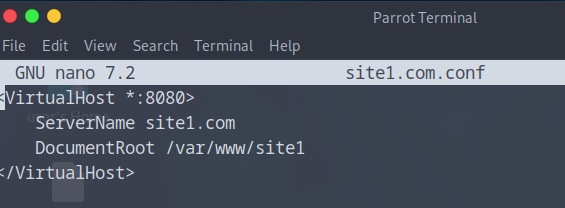
La même chose pour le site2
- Sudo nano site2.com.conf
- Bien mettre le <VirtualHost * :8081> pour le site 2
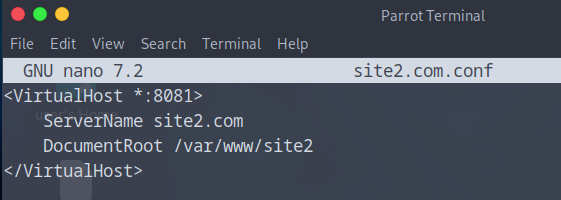
Voilà nos deux Virtualhosts sont créés sur notre serveur Web 1 faire exactement la même chose sur le Web 2.
5.6 Création des dossiers pour nos index.html
Créer les dossiers :
Cette commande va créez les deux chemins d’accès pour vos sites.
- Sudo mkdir -p /var/www/site1 /var/www/site2

Créer un index.html spécifique dans chaque :
Cela va nous permettra d’avoir accès leurs index.html directement dans leur propre site.
echo « Bienvenue sur SITE1 – WEB1 » | sudo tee /var/www/site1/index.html

echo « Bienvenue sur SITE2 – WEB1 » | sudo tee /var/www/site2/index.html

5.6 Activer les sites :
Cela va nous permettre à Apache de prendre par default le site demandé.
- sudo a2ensite site1.com.conf
- sudo a2ensite site2.com.conf
- sudo systemctl reload apache2
Répète les étapes sur le serveur WEB2 en changeant les messages dans index.html.
Exemple : echo « Bienvenue sur SITE2 – WEB2 » | sudo tee /var/www/site2/index.html
6. Configurer le fichiers hosts
Pour cela il faudra le faire sur chacune de vos VMS (donc les 3 vms) cela nous permettra d’avoir dans notre navigateur site1.com a la place d’une adresse ip 192.168.1.100.
- Sudo nano /etc/hosts
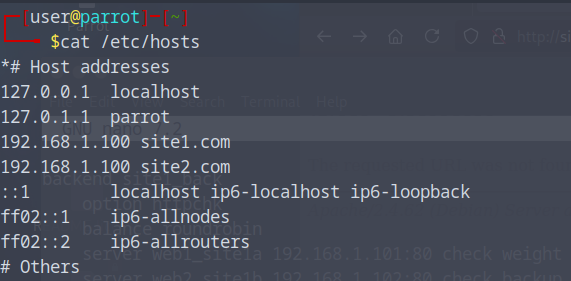
Et ajouter ceci : (192.168.1.100 est l’adresse IP fixe de mon serveur HAProxy qu’on mettra en place bientôt)
– 192.168.1.100 site1.com
– 192.168.1.100 site2.com
7. Installer et configurer HAProxy
7.1 Installer HAProxy sur VM1 (HAProxy)
Connecter vous à votre VM HAProxy et nous allons installer HAProxy
Pour cela ouvrezz votre terminal et saisissez les commandes suivantes.
- Sudo apt update
- Sudo apt install haproxy -y
7.2 Configurer HAProxy
Pour configurer notre HAProxy il nous suffit d’aller chercher le haproxy.cfg
- Sudo nano /etc/haproxy/haproxy.cfg

C’est ici qu’on va mettre notre Frontend et notre Backend ainsi que nos commandes ACL.
Ne faites pas attention aux adresses IP pour le moment car les IP que vous allez mettre est en rapport avec vos Serveurs WEB
Je vous mets la config pour le projet ce qui est en Rouge est à changer à fonction de vos choix
# Configuration personnalisé
# FRONTEND – point d’entrée HTTP
frontend http_front
bind :80 # Le frontend écoute sur le port 80 pour les connexions http
# ACLs (Access Control Lists) pour détecter les noms de domaine
acl is_site1 hdr(host) -i site1.com # Si l’en-tête « Host » est « site1.com »
acl is_site2 hdr(host) -i site2.com # Si l’en-tête « Host » est « site2.com »
acl no_primary nbsrv(Web1_backend) lt 1 # « no_primary » devient vrai si tous les serveurs Web1 sont down
# Si Web1 est indisponible ET que la requête est pour site1 ou site2, redirige vers le backend_BackupWeb2
use_backend BackupWeb2_backend if no_primary is_site1 or no_primary is_site2
# Si le WEB1 disponible, si site1 ou site2 est demandé, utilise le backend principal
use_backend Web1_backend if is_site1 or is_site2
# BACKEND principal pour site1.com et site2.com 50/50
backend Web1_backend
balance roundrobin # Répartition de charge entre les serveurs (équilibrée)
option httpchk GET / # Vérifie la santé des serveurs en envoyant une requête GET /
server web1_site1 192.168.1.101:8080 check weight 50 # Serveur1 pour site1, pondération à 50
server web1_site2 192.168.1.101:8081 check weight 50 # Serveur1 pour site2, même IP mais port différent
# BACKEND de secours utilisé si Web1 est down 80 site1 / 20 site2
backend BackupWeb2_backend
balance roundrobin # Même type de répartition
option httpchk GET / # Vérification de santé identique
server web2_site1 192.168.1.102:8080 check weight 80 # Serveur de secours pour site1
server web2_site2 192.168.1.102:8081 check weight 20 # Serveur de secours pour site2
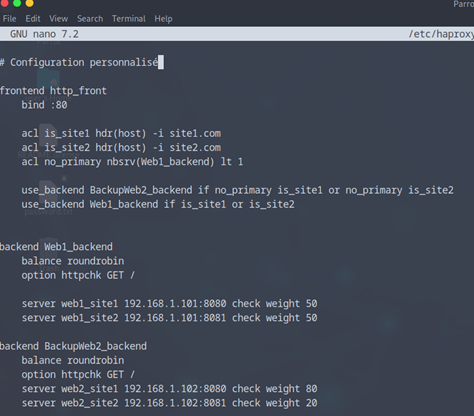
Maintenant n’oubliez pas de sauvegarder et de redémarrez votre HAProxy.
- sudo systemctl restart haproxy
8. Configuration des adresses IPS Statique
Tout d’abord pour commencer, il va falloir éteindre toutes vos VMS VMware et changer le mode Bridged en VMnet1
Connectez-vous sur votre VM HAProxy nous allons lui donner une adresse statique pour éviter tous les problèmes.
Rien de plus simple vous rendre ici pour vous mettre en IP statique
- Sudo nano /etc/network/interfaces
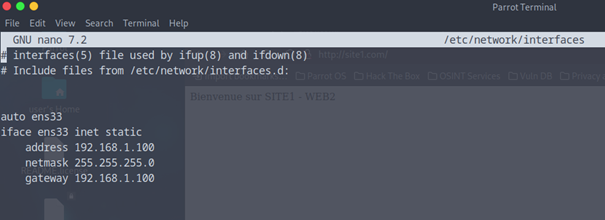
Ensuite voila comment le mettre en statique, pour mon cas mon serveur est en 192.168.1.100
N’oubliez pas de faire un « ip a » pour avoir votre interface, dans mon cas c’est ens33
auto ens33
iface ens33 inet static
address 192.168.1.100
netmask 255.255.255.0
gateway 192.168.1.100
Maintenant reproduisez cela sur vos deux serveurs WEB.
Un petit rappel :

9. Test
Aller sur votre serveur HAProxy pour tester.
Ouvrer un navigateur et saisissez « site1.com » ou « site2.com »
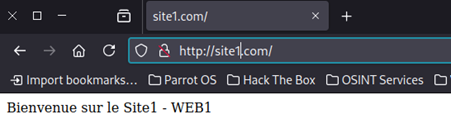
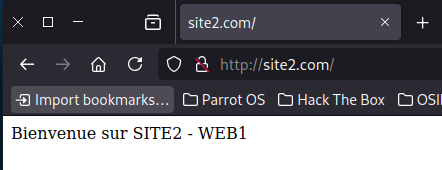
La mes deux sites marche très bien site1 et site2 de mon serveur WEB 1.
Exemple quand je suis sur le site1.com et que je rafraichi la page je passe de force sur le site2.com vu que je suis en loadbalancing 50/50.
Maintenant que ce passe t’il si j’éteins ma VM WEB1 ?
On peut voir que si je rafraichi ma page je vais avoir pendant quelques secondes une internal error, mais que mon serveur WEB2 va prendre le relai. On appelle ça de la redondance.
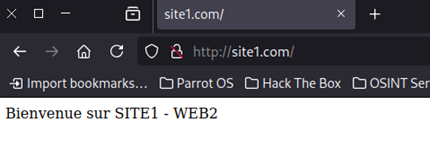
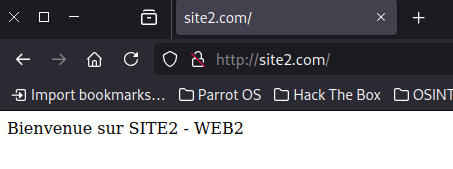
Même principe que le WEB1 mais je suis en loadbalancing pondéré en site1.com 80% et site2.com 20%, 4 connexions iront sur le site1 et 1 sur le site2 d’où le 80/20.
10. Questions
Que se passe-t-il si HAProxy est indisponible ?
Si HAProxy tombe en panne, tout le système de répartition de charge et de haute disponibilité devient inaccessible.
Aucune requête utilisateur ne pourra atteindre les serveurs web, même s’ils sont fonctionnels.
Pourquoi ?
Car tout le trafic passe par HAProxy, c’est le single point of entry.
Pourquoi utilise-t-on des ACL dans la configuration HAProxy ?
Les ACL (Access Control List) permettent de filtrer et diriger les requêtes en fonction de certaines conditions.
acl site1_acl hdr(host) -i site1.com
Cette ligne créez une condition qui est vraie si l’en-tête Host vaut site1.com.
use_backend site1_back if site1_acl
Cela permet de rediriger la requête vers le bon backend selon le site demandé par le client
Pratique pour gérer plusieurs sites ou règles différentes sur une seule IP !
3. Quelle est la différence entre « roundrobin » et « leastconn » dans la répartition de charge ?

4. A quoi sert le port 8404 d’HAProxy ? Faites une démonstration
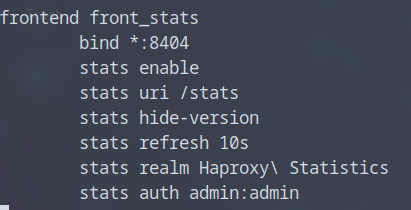
Il est souvent utiliser pour voir les stats donc je vais aller dans le fichiers haproxy.cfg pour pouvoir acceder au stats.
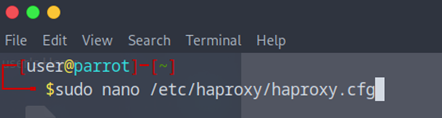
Et je vais rajouter un bloc pour avoir aux stats, j’ai mis le port 8404 et en url /stats
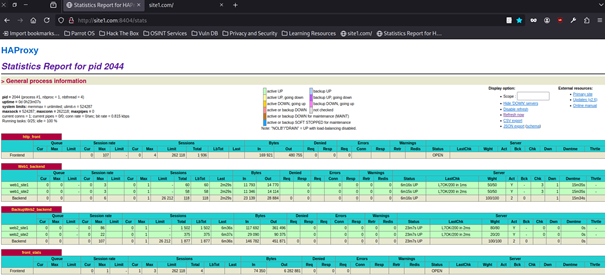
Voilà ce que ça donne en entrant l’URL site1.com ou site2.com :8404/stats
11.Partie 2 : Simulation d’attaque et protection avec Fail2Ban
11.1 C’est quoi Slowloris ?
Slowloris est un type d’attaque par déni de service (DoS) très sournois.
Plutôt que d’inonder un serveur avec du trafic massif comme un DDoS classique, il l’étouffe lentement.
- Faire tomber un serveur web (Apache, Nginx, etc.) avec un minimum de trafic.
Comment ça marche ?
- L’attaquant envoie des connexions HTTP partielles au serveur.
- Il n’envoie jamais la requête complète, mais garde la connexion ouverte en envoyant des headers très lentement, genre 1 toutes les 10 secondes.
- Le serveur pense que c’est une vraie requête lente et garde la connexion ouverte.
- L’attaquant ouvrez des centaines (ou milliers) de ces connexions lentes.
- Résultat : les connexions valides des vrais utilisateurs ne passent plus, car le serveur a atteint sa limite de connexions.
Comment s’en protéger ?
- Fail2Ban : détecter et bannir les IP qui abusent.
- Timeouts agressifs sur les headers dans Apache/Nginx.
- Reverse proxy (comme HAProxy ou Cloudflare) pour filtrer.
- Limiter le nombre de connexions simultanées par IP.
11.2 Télécharger Slowloris
Sur votre Kali on va téléchargé Slowloris, ouvrezz votre terminal et saisissez :
- Sudo git clone https://github.com/gkbrk/slowloris.git
- cd slowloris
Une fois que vous avez téléchargé Slowloris pensez à remettre votre VMware en VMnet1 et attribuer lui une adresse ip static
Ma VM Kali aura l’IP static 192.168.1.199
11.3 Simulation d’une attaque Slowloris
Voici la syntaxe pour envoyer une attaque :
- Sudo python3 slowloris.py 192.168.1.100 -p 80
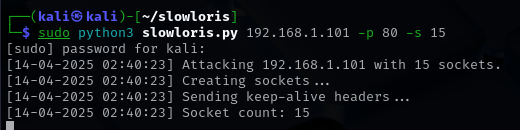
Les Options de Slowloris :

11.4 Observer l’impact d’une attaque sur HAProxy
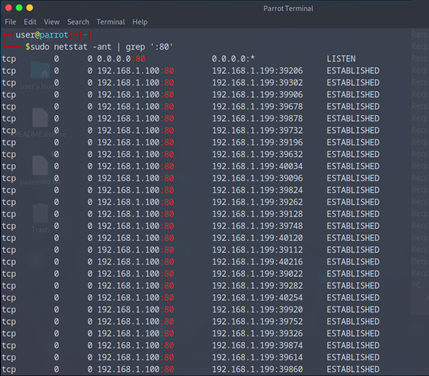
On peut voir avec la commande netstat -ant | grep ‘:80’
Toutes les connexions de la Kali en Etablished
11.5 Sur les Serveurs Web, Installer Fail2Ban
Pour cela on va commencer à installer Fail2ban sur nos serveurs WEB1 et WEB2
- Ouvrer votre terminale et saisissez la commande pour installer Fail2Ban
- Sudo apt update && sudo apt install fail2ban -y
Maintenant qu’il est installés passons à la présentation de Fail2Ban.
11.6 Présentation de Fail2Ban
Fail2Ban est un outil de sécurité pour les serveurs Linux.
Il protège automatiquement les services (comme SSH, Apache, FTP…) contre les attaques malveillantes.
- Surveillance des logs
Fail2Ban lit en temps réel les fichiers de logs (ex : /var/log/auth.log, /var/log/apache2/error.log…).
- Détection de comportements suspects
Il repère des modèles d’erreurs, comme :
Trop de tentatives de connexion SSH échouées
Requêtes HTTP suspectes (attaques bruteforce ou DoS)
Réaction automatique
Si une IP dépasse un seuil :
Elle est bannie via iptables (ou autre backend)
Le ban dure un temps configurable (par défaut : 10 minutes)
Structure de Fail2Ban
Filtres : définissent quoi surveiller dans les logs (ex : sshd, apache-auth, etc.)
Jails : combinent un filtre + une action à prendre (ex : bannir via iptables)
Actions : ce que Fail2Ban fait quand une IP est suspecte (ban, mail, etc.)
Pourquoi l’utiliser ?
Protection automatisée contre :
- Brute-force SSH
- Attaques sur Apache/Nginx
- Scripts malveillants
- Slowloris & DoS (avec configuration personnalisée)
Réduit les risques sans charge humaine
Très léger, facile à configurer, et modulaire
11.7 Configurer Fail2Ban contre Slowloris
Maintenant il faut qu’on adapte notre Fail2Ban pour nos serveur Apache2.
La configuration que tu ajoutes dans le fichiers /etc/fail2ban/jail.local sert à protéger ton serveur SSH contre les tentatives de connexion malveillantes ou bruteforce grâce à Fail2Ban, un outil de sécurité.
Toujours dans le terminal :
- Sudo nano /etc/fail2ban/jail.local
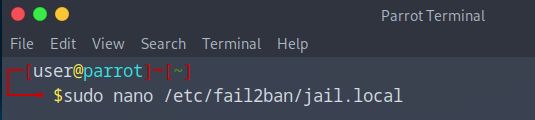
On va y rajouter quelque ligne de commande à l’intérieur :
[sshd]
enabled = true
port = ssh
logpath = /var/log/auth.log
backend = systemd
[slowloris]
enabled = true
port = http,https
filter = slowloris
logpath = /var/log/apache2/access.log
bantime = 3600
maxretry = 5
findtime = 60
action = iptables-multiport
Si une IP fait trop de tentatives de connexion SSH échouées, elle sera automatiquement bannie (bloquée par iptables ou firewall).
Cela protège ton serveur contre les attaques automatisées de type bruteforce.
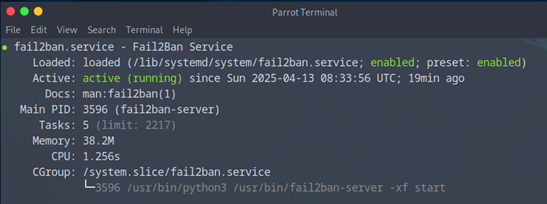
Il vous reste plus qu’à faire un :
- Sudo systemctl restart fail2ban
- Ainsi qu’un sudo systemctl status fail2ban pour voir si tout marche bien
11.8 Crée un filtre pour Slowloris
Crée un fichiers de filtre dans sudo nano /etc/fail2ban/filter.d/slowloris.conf avec le contenu suivant :
[Definition]
failregex = ^<HOST> -.* »(GET|POST).*HTTP.*$
ignoreregex =
On va voir notre Fail2Ban-client avec :
- Sudo Fail2Ban-client status slowloris
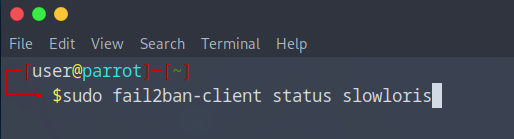
Pour le moment tout est clean.
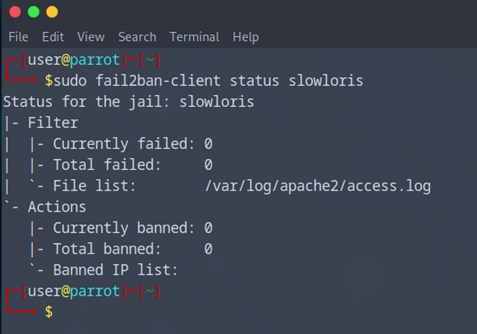
Maintenant passons au test !
12. Test
12.1 Test demander :
– Puis, relancer l’attaque avec Slowloris, tester la protection Fail2Ban, vérifier les IP bannies et consulter les logs de Fail2Ban.
-Modifier les paramètres de Slowloris (intervalle, port) pour tester différentes intensités d’attaque.
-Faites une capture Wireshark lors de l’attaque.
12.2 Simulation d’attaque et de protection Fail2Ban (+capture Wireshark)
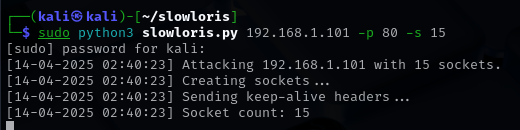
Pour commencer je lance une attaque avec Slowloris sur le port 80 avec 150 requêtes
- Sudo python3 slowloris.py 192.168.1.101 -p 80 -s 150
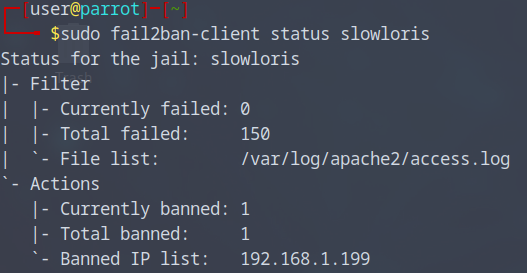
Je regarde si mon Fail2Ban marche correctement, on peut voir qu’il a ban mon adresse IP de ma machine Kali pour 3600s.
Voici une capture de mon Wireshark en HTTP
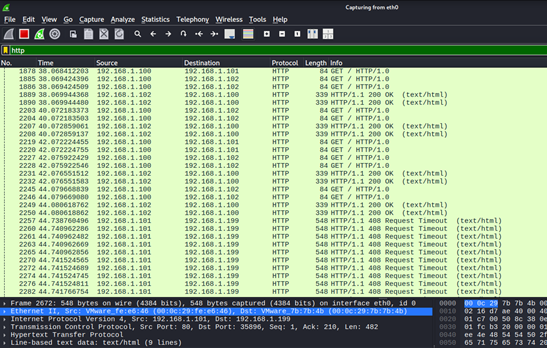
13. Questions
1.Pourquoi le code HTTP 499 est-il utilisé dans le filtre Fail2Ban ?
Le code HTTP 499 est un code non standard utilisé par Nginx pour indiquer que le client a fermé la connexion avant que le serveur n’ait pu envoyer une réponse. Il n’est pas défini dans la norme HTTP, mais il est couramment utilisé dans des environnements où Nginx est configuré comme serveur proxy ou inverse.
Pourquoi Fail2Ban l’utilise-t-il ?
- Détection d’une attaque Slowloris : Lors d’une attaque Slowloris, un client ouvrez plusieurs connexions HTTP vers le serveur, mais il les maintient ouvertes sans envoyer de requêtes complètes.
- Si un client ferme la connexion avant que le serveur n’ait pu répondre (souvent en raison du délai de l’attaque Slowloris), le serveur enregistrera un code HTTP 499. Fail2Ban utilise donc ce code pour identifier les connexions fermées prématurément et déclencher une action (bannissement de l’IP) sur les attaques Slowloris.
- Indicateur de comportement anormal : Lorsqu’un grand nombre de connexions sont fermées prématurément, cela peut être le signe d’une tentative d’attaque par épuisement des ressources du serveur. Fail2Ban peut alors utiliser ce code HTTP pour cibler ces comportements et bloquer les IP suspectes.
2. Comment adapteriez-vous la configuration de Fail2Ban pour bloquer une attaque plus rapidement ?
Pour rendre la protection Fail2Ban plus réactive et bloquer les attaques plus rapidement, vous pouvez ajuster certains paramètres dans la configuration de la jail. Voici quelques exemples de modifications :
a) Diminuer le délai de findtime :
Le paramètre findtime définit la période pendant laquelle Fail2Ban compte les tentatives de connexion échouées avant de déclencher une action. En diminuant cette période, Fail2Ban sera plus réactif aux attaques.
- findtime = 30 # réduire de 60 à 30 secondes
Cela signifie que Fail2Ban comptera les tentatives échouées dans une fenêtre de 30 secondes au lieu de 60.
b) Réduire le nombre de tentatives maxretry :
Le paramètre maxretry définit le nombre maximum de tentatives avant qu’une IP soit bannie. Pour réagir plus rapidement à une attaque, vous pouvez réduire ce nombre.
- maxretry = 3 # réduisez de 5 à 3 tentatives
Cela limite le nombre d’échecs autorisés, donc une IP sera bannie plus rapidement après un petit nombre de connexions suspectes.
c) Réduire la durée du bantime :
Le paramètre bantime définit la durée pendant laquelle une IP est bannie après avoir dépassé le seuil de maxretry. Pour une réponse plus rapide, vous pouvez définir un bannissement plus court, mais vous devrez peut-être aussi ajuster les autres paramètres pour que la protection soit efficace.
- bantime = 600 # bannissement de 10 minutes au lieu de 1 heure
d) Activer des actions plus sévères :
Vous pouvez également spécifier des actions plus strictes en utilisant action = iptables-all-ports (pour bloquer toutes les connexions de l’IP malveillante) ou ajuster la règle action pour que l’IP soit bloquée de manière plus agressive.
- action = iptables-all-ports
3. Quelles sont les limites de Fail2Ban face à une attaque DDoS ?
Bien que Fail2Ban soit un excellent outil pour se protéger contre des attaques comme les attaques par force brute ou les attaques de type Slowloris, il présente certaines limites face à une attaque DDoS (Distributed Denial of Service) :
a) Les attaques DDoS utilisent un grand nombre d’IP :
Fail2Ban fonctionne en bloquant les IP sources de comportements malveillants. Cependant, dans une attaque DDoS, des milliers (voire des millions) d’IP différentes peuvent être utilisées pour envoyer des requêtes. Par conséquent, Fail2Ban ne sera pas capable de bloquer efficacement toutes les IP malveillantes, car il doit surveiller et bloquer chaque IP individuellement.
b) Impact sur les ressources système de Fail2Ban :
Lors d’une attaque DDoS, la quantité de connexions et de journaux générés peut être très élevée. Fail2Ban doit analyser un grand nombre de connexions et de requêtes en temps réel, ce qui peut saturer les ressources système et rendre Fail2Ban moins efficace. Il peut également devenir difficile pour Fail2Ban de traiter toutes les tentatives d’attaque, surtout si les logs sont générés à un rythme rapide.
c) Scalabilité limitée :
Fail2Ban fonctionne bien sur des systèmes de taille petite à moyenne. Cependant, dans des environnements à grande échelle ou face à des attaques DDoS de grande envergure, Fail2Ban peut avoir du mal à suivre le volume massif de requêtes et à appliquer des mesures de protection suffisantes.
d) Solutions DDoS sophistiquées :
Certaines attaques DDoS peuvent utiliser des techniques comme la rotation d’IP ou l’utilisation de botnets (réseaux de machines compromises) pour rendre difficile la détection et le blocage par Fail2Ban. Dans ces cas, Fail2Ban pourrait être inefficace, car il dépend de l’identification des IP qui peuvent changer constamment.
Share this content:











Laisser un commentaire